The Problem with AI in Public
Have you ever tried to use Gemini or ChatGPT while walking on the street? It is quite awkward. You either look like you are staring at a text box, completely out of touch with the real world, or you look like you are on a mission to press a push-to-talk button on a walkie-talkie.
These are not just minor issues to be solved. They are major issues that prevent the full integration of AI into our everyday lives. We have the technology, but we do not have the interaction model right. We are making ourselves adapt to the technology instead of making the technology adapt to us.
This brings me to the concept of invisible computing, which is “hidden yet present.” The goal is to use technology in a way that feels as natural as having a conversation with a friend walking alongside you.
Jemmie: A Different Approach

Our project, Jemmie, is a direct response to these challenges. Built specifically to participate in the Gemini Live Agent Challenge, it is based on a simple concept that has a profound impact:
- Native Phone Call Integration: Jemmie integrates seamlessly into iOS CallKit, so you will not stand out.
- Smooth, Natural Speech: Thanks to ultra-low latency, you can interrupt a sentence as naturally as in a real conversation. No stiff, robotic silences.
- Hands-Free Convenience: Pop on your AirPods, and you are free to move about. No screens, no buttons, just the agent waiting for you when you need it.
It is not about building a more intelligent agent. It is about building a more intuitive interface to the intelligent agent we already have. We have the brains. We just need to make it invisible.
Architecture Overview
The system runs on WebSocket for real-time bidirectional communication between an iOS client and a Python backend.
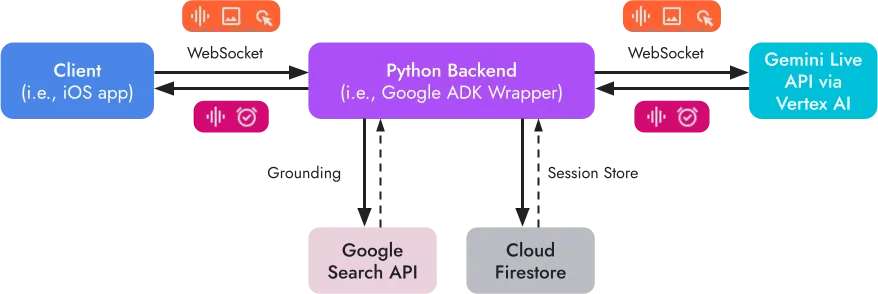
WebSocket architecture showing the flow between iOS client, Python backend, and Google Cloud services (Gemini Live API, Firestore).
Message formats are simple. Most messages use JSON format and carry a type and a payload. Audio is an exception and uses binary frames sent using websocket.send_bytes(), which bypasses base64 encoding and decoding.
This matters because when you are having a voice conversation, every millisecond counts.
With the basic architecture outlined, the question becomes: how do you build a system that scales and grows? That is what we will explore next.
Extensibility Through Actions and Events
The main concept of Jemmie is extensibility. The goal is to make the system improve with new capabilities without the need for large-scale architectural changes. To achieve this, we have made a clean split between the client’s requests for actions and the server’s responses with events.
Client Actions
Client actions are the operations a user can start from their device. Currently, the available operations are sending a test message back (echo), sharing your GPS location, and adjusting the volume.
The system uses a registry-based architecture, where every action handler resides inside src/actions/client/ and is registered with a decorator.
@register_client_action("ACTION_TYPE")
class MyActionHandler(ClientActionHandler):
def execute(self, payload: dict) -> None:
# Handle the action
passEvery handler extends ClientActionHandler and must implement the execute() method. Optionally, the handler can provide a context_template to add context to the agent’s knowledge base.
The process is straightforward. A client action is sent over the WebSocket to the FrameEngine, which uses the ActionPipeline to deliver it to the correct ClientActionHandler. The result is then queued for the Gemini agent to process. Simple, right?
Server Events
On the other hand, server events refer to the messages that the agent can send to the client. These range from simple text and audio playback to more complex operations such as performing a web search, using a timer, and asking for permission to use the camera.
Events are structured as OutboundFrame objects:
class OutboundFrame(BaseModel):
type: str # Event type
payload: dict # Event-specific data
session_id: str # Session identifier
ts: int # Timestamp (auto-generated)The important point to note is that server events are given as a tool to the Gemini agent to use. This provides the LLM with the opportunity to decide when to execute actions such as opening a URL or setting a reminder, thus giving the agent autonomy in how it interacts with the user’s device.
Data Models
The schema layer remains deliberately lightweight. The core models are defined in src/schema/frames.py:
- ClientFrame: the base model for client actions, with a
typeand apayload - ImageFrame: the model for image data, which includes the raw bytes and the mime-type
- RawAudioFrame: the model for audio data, which includes the pcm bytes and a sample rate from 8000 to 48000 Hz
Sessions are persisted with a SessionDocument in src/schema/session.py, which includes the device_id, session_id, the current state, and agent_context to ensure the conversation remains coherent.
Key Architecture Patterns
Looking back at these architecture decisions, a few patterns stood out that we found particularly useful.
Registry Pattern
The Registry Pattern is used to register actions and events using decorators when modules import. In other words, when you need to add a new capability to the system, you simply add a new handler class and decorate it. The system will automatically recognize and route to it.
Pipeline Architecture
Separating audio and action streams is beneficial. Audio goes through a streaming-optimized pipeline, while actions go through a separate pipeline optimized for validation and routing.
Queue-Based Communication
Various parts of the system communicate using async queues. The live_request_queue, outbound_queue, and content_queue all serve as buffers between different components. They allow each part to function independently without conflicting with others.
ADK Integration
The ADK is integrated using a tool called QueueBridge, which bridges ADK’s LiveRequestQueue to our internal queues. This layer of indirection ensures that the voice agent implementation is not tightly coupled to the LLM implementation.
Closing Thoughts
That concludes what we wanted to share about this project. Building Jemmie has taught us that the real challenge of voice AI is not the AI technology itself, but everything around it: latency requirements, interruption logic, session management, and above all, making it all seem seamless and natural.
The architecture we have outlined is by no means the only way to achieve the desired outcome. There are edge cases to be addressed, events to be added, and the constant pressure to reduce latency even further. But the patterns we have outlined have been consistently effective building blocks.
If there is one lesson to be learned, it is the importance of extensibility. Extensibility is something you should build into your system, not something you add later. The use of the decorator pattern for the registry and the distinction between actions and events has allowed new capabilities to be added with just a few lines of code.
The dream of invisible computing is still just a dream. Projects like Jemmie are helping to make it a reality, experimenting to find out what it takes to make AI technology seem less like something you use and more like something that is simply there when you need it.
Thanks for your time. If you are curious to see the code, the project was built as part of the Gemini Live Agent Challenge using Google’s ADK with Vertex AI on Google Cloud. The code is available on GitHub: frontend and backend.